Text-to-SQL as a Foundation for Trustworthy AI
Converting natural language queries to SQL for structured data access and grounding
Trust in AI systems does not come from clever prompting alone. While large language models (LLMs) can generate compelling prose and plausible answers, their reliability often erodes when they interact with structured enterprise data. Hallucinations, schema mismatches, and ambiguous interpretations remain common failure modes.
A more durable path to trustworthy AI is to wrap natural language interactions in a Text-to-SQL translation layer-one that is schema-aware, provenance-rich, and grounded in custom-trained models. This approach turns AI from a speculative answer engine into a verifiable interface, where every output can be traced to a deterministic query against an authoritative data source.
LLMs perform more accurately when they truly understand the database schema-its tables, fields, relationships, and constraints. By directly embedding schema metadata into prompts or leveraging retrieval of schema documentation, the LLM gains critical context to generate precise, semantically valid SQL. This schema grounding mitigates hallucination and enhances every step of reliability-from query correctness to downstream data integrity.
Don’t just lean on generic structured prompting. Instead, wrap carefully designed prompts into a text‑to‑SQL layer, anchoring in schema and using robust frameworks to produce trustworthy outputs.
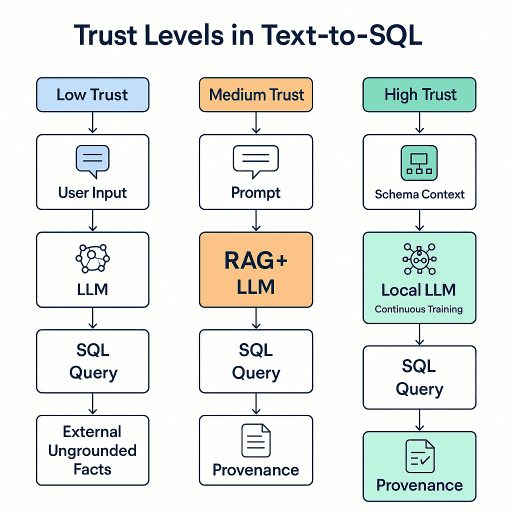
Why Text-to-SQL Improves Trust
Deterministic Answers from Authoritative Data
When an LLM generates a SQL query instead of a direct answer, the truthfulness of the response depends on the database, not the model’s memory. This removes ambiguity: the LLM is no longer “inventing” facts but instead expressing a structured request to an agreed-upon source of truth.
Generic LLMs, even with large context windows, are not optimized for domain-specific schemas or organizational naming conventions. Custom-trained Text-to-SQL models bring three advantages:
- Domain-specific Vocabulary. Trained on your schema, documentation, and query history, a model learns to map industry jargon directly to the right tables and fields.
- Optimized Query Patterns. Fine-tuning or instruction-tuning can teach models preferred join strategies, filtering conventions, and aggregation styles aligned with your performance and security requirements.
- Reduced Prompt Engineering Overhead. Instead of crafting complex prompts for every query, a well-trained model already understands your schema, cutting down on prompt complexity and execution latency.
Schema Awareness Prevents Hallucinations
A schema-aware Text-to-SQL model knows the available tables, relationships, and constraints. It avoids referencing non-existent fields or generating logically impossible joins. By constraining generation to the known schema, you reduce hallucination rates dramatically.
A trustworthy Text-to-SQL architecture is more than “ask the LLM for SQL.” It should be a multi-stage, schema-anchored pipeline:
-
Schema Extraction and Representation
- Store table/column definitions, foreign key relationships, and indexes in a machine-readable format (JSON, YAML, or SQL DDL).
- Embed schema in a vector store for retrieval-augmented generation (RAG).
-
Natural Language to SQL Generation
- Use fine-tuned or instruction-tuned models specialized in Text-to-SQL.
- Employ constrained decoding to enforce syntactic correctness.
-
Validation and Correction Loop
- Run the generated SQL against a syntax checker or test database.
- If errors occur, feed the error messages back into the model for correction.
-
Execution with Safeguards
- Apply role-based access control to prevent data leakage.
- Use query analyzers to block dangerous operations (e.g., unbounded DELETEs).
-
Response Generation with Provenance
- Return results alongside the executed SQL.
- Store queries and results in provenance-enriched Markdown for downstream audit and reuse.
Auditability and Compliance
SQL queries can be logged, versioned, and audited. When used in regulated environments-healthcare, finance, defense-this is critical. You can trace every AI-driven answer back to the exact query and dataset used, satisfying governance and compliance requirements.
Prompting LLMs directly against raw enterprise data is an invitation to inconsistency. Wrapping those prompts in a schema-aware, custom-trained Text-to-SQL layer turns unstructured requests into deterministic, auditable queries. This approach aligns perfectly with the principles of trustworthy AI: verifiable outputs, provenance tracking, and governance-ready architecture.
For AI-native engineering teams, Text-to-SQL is not just a convenience feature-it’s a structural requirement for building systems that users can trust with their most critical data.
Open-Source and Commercial Foundations
Organizations seeking control and transparency should begin with open-source frameworks:
- PremSQL: A fully local, open-source Text-to-SQL library optimized for security and customization. Ideal for environments where data privacy is paramount.
- Vanna (MIT-licensed): A Python RAG framework enabling SQL generation from natural language. Helps ground prompts via retrieval, often including schema docs.
- Quepy: A customizable framework for mapping natural language to database queries-even if older, notable for rule-based precision tuning.
- CodeS (open-source LLM): A specialized family of language models (1B–15B parameters) pre-trained for Text-to-SQL using SQL-centric corpora and schema-aware techniques. Excellent for fine‑tuned, private performance.
- BASE-SQL: A novel pipeline leveraging schema linking, candidate generation, revision, and merging. Uses fine-tuning of the open-source Qwen2.5‑Coder‑32B‑Instruct LLM. Achieves impressive benchmark accuracy with efficiency and transparency.
- UniSAr: Enhances autoregressive LLMs by making them aware of structure: encoding schema context, enforcing constrained decoding, and intelligently completing JOINs. Non‐invasive but powerful schema grounding.
Commercial options offer governance, UI, and enterprise-scale integration:
- AWS + Bedrock + Claude 3.5 Sonnet: A managed pipeline using RAG-schema-aware embeddings via Amazon Titan, and LLM generation of SQL, tightly integrated with robust enterprise tooling.
- Shakudo’s Enterprise Text-to-SQL: Offers LLM-based SQL with semantic consistency, custom fine-tuning, query-level security, and transparent translations-ideal for regulated environments.
- SelectStar’s Landscape Overview: Highlights modern tools that are cross-platform and metadata/schema-aware, integrating data catalog and orchestration layers for governed, safe Text-to-SQL experiences.
Hybrid strategies-open-source core with commercial wrappers-often provide the best mix of control and productivity.
Engineering Pattern for Schema-Aware Text-to-SQL
A trustworthy Text-to-SQL architecture is more than “ask the LLM for SQL.” It should be a multi-stage, schema-anchored pipeline:
- Schema Extraction and Representation – Maintain a machine-readable schema (JSON/YAML/DDL) as the source of truth.
- Natural Language to SQL Generation – Use fine-tuned or instruction-tuned models specialized for SQL.
- Validation and Correction Loop – Apply syntax checkers, test DB execution, and iterative correction.
- Execution with Safeguards – Enforce role-based access control and query safety filters.
- Response with Provenance – Store all steps in Markdown with frontmatter for full auditability.
Here’s the new whitepaper section you can insert after the RAG pattern - it frames best practices for general-purpose LLMs in Text-to-SQL and explains why fine-tuning on your schema + historical queries is the ultimate path to trust in multi-tenant, fine-grained authorization contexts.
Start with a Controlled General-Purpose LLM Setup
When you begin implementing Text-to-SQL for trustworthy AI, general-purpose LLMs like OpenAI’s GPT-4o or Anthropic’s Claude 3.5 Sonnet can provide excellent baseline performance if integrated with discipline:
-
Tight Prompting. Always wrap user questions in a strict, schema-aware prompt template. Include:
- Explicit instructions to only use provided schema.
- Rules for safe query generation (e.g., no
DELETE, no cross-tenant joins without authorization checks). - Domain-specific query examples for few-shot learning.
-
Retrieval-Augmented Generation (RAG). Use a schema retriever to feed the LLM only the relevant subset of tables and columns per query (as in the RAG pattern earlier). Benefits:
- Reduces hallucination risk.
- Improves token efficiency and latency.
- Makes outputs more consistent.
-
Validation Loops. Incorporate:
- SQL syntax checkers.
- Test execution against a sandbox DB.
- Automatic correction cycles if the first attempt fails.
-
Provenance Logging. Store the query, schema subset, prompt, and execution result in provenance-enriched Markdown for traceability and audits.
Recognize the Limits of General-Purpose Models
Even with tight prompting and RAG, general-purpose LLMs have blind spots:
- Authorization Context: They cannot inherently understand which tenant’s data a user is allowed to access.
- Policy Awareness: They may generate queries that bypass row-level security or ignore business rules.
- Terminology Drift: They can misinterpret organization-specific naming conventions over time.
- Context Fatigue: For large schemas, RAG still relies on semantic matching, which can miss relevant but less obvious tables.
These limitations mean that while general-purpose LLMs can simulate trustworthy behavior, they do not intrinsically understand your domain’s constraints.
Why Fine-Tuning Is the Next Step
To achieve true trust alignment, you must train a custom Text-to-SQL model on your own schema + historical queries + authorization rules. Benefits:
-
Schema Alignment. The model learns the exact structure, relationships, and naming conventions of your database - no more ambiguity between similar-sounding fields.
-
Authorization Preservation. Multi-tenancy and fine-grained permissions become part of the model’s learned behavior. For example:
- The model never generates a cross-tenant join unless a special administrative role is present.
- Queries automatically include
WHERE tenant_id = :currentTenantfilters where required.
-
Performance Optimization. The model adopts your preferred query patterns, indexing strategies, and optimization hints.
-
Reduced Prompt Complexity. Once fine-tuned, you no longer need heavy prompt engineering for every query - the model defaults to compliant, efficient SQL generation.
Trust Through Alignment
When a Text-to-SQL model is trained on your schema and your rules:
- Multi-Tenancy Enforcement becomes automatic.
- Fine-Grained Authorization is preserved in query generation.
- Business Logic Compliance is built into the model’s “instincts,” not just bolted on via prompts.
- Regulatory Trust increases because every query aligns with documented policy.
In effect, fine-tuning turns trust from a runtime constraint into a model-native behavior.
Enhancing Trust with RAG Schema Retrieval
Large schemas overwhelm LLMs and increase costs. Retrieval-Augmented Generation (RAG) solves this by retrieving only the most relevant subset of the schema for each request.
Benefits:
- Reduced Error Surface – Less irrelevant context for the LLM to misuse.
- Lower Costs – Smaller token payloads.
- Improved Accuracy – Focused context drives more consistent results.
- Provenance Clarity – Logs show exactly which schema subset informed each query.
Best Practices for Using General-Purpose LLMs in Text-to-SQL
When starting, general-purpose LLMs (e.g., GPT-4o, Claude 3.5 Sonnet) can perform well if integrated with discipline:
- Tight Prompting – Strict templates with explicit schema rules.
- RAG Context – Schema subset retrieval per query.
- Validation Loops – Automatic syntax checking and error correction.
- Provenance Logging – Every step recorded in auditable Markdown.
Limits:
- They cannot inherently enforce multi-tenancy or fine-grained permissions.
- They may misinterpret domain-specific terminology.
- They rely on runtime constraints rather than intrinsic policy understanding.
Even the best prompts in the world still delegate trust to an external horizontal model whose training data and retrieval capabilities you do not control. This means you cannot fully prevent the injection of external, ungrounded facts into query generation.
Fine-Tuning for Schema and Policy Alignment
To achieve true trust alignment, fine-tune a Text-to-SQL model on your schema, historical queries, and authorization rules.
Benefits:
- Schema Alignment – Learns exact structures, relationships, and naming conventions.
- Authorization Preservation – Embeds multi-tenancy and role-based constraints into query generation.
- Performance Optimization – Adopts your preferred join patterns and indexing strategies.
- Reduced Prompt Overhead – Compliant query behavior becomes the model’s default.
Dataset Preparation Script (TypeScript/Deno):
- Reads historical queries and schema.
- Generates JSONL training records with prompt-completion pairs.
- Includes multi-tenant and role-specific examples for policy learning.
Fine-tuning moves policy enforcement from the prompt into the model’s instincts.
The Ultimate Trust Model: Custom Local LLMs
The highest level of trust comes when the model itself is fully local, trained exclusively on your own schema, queries, and policies, with no access to external, ungrounded facts. In regulated, multi-tenant environments, traditional general-purpose LLMs (e.g., OpenAI, Claude) are inadequate for the highest trust scenarios. Even with careful prompting and schema-aware RAG, horizontal models:
- Cannot guarantee exclusion of ungrounded, external knowledge.
- Are dependent on vendor-controlled infrastructure and training data.
- Lack built-in awareness of tenant-level access controls and business rules.
The ultimate trust model is therefore built on:
- Local-only model hosting (air-gapped or network-restricted).
- Fine-tuning with in-domain schema, queries, and policies.
- Continuous retraining based on approved queries and outcomes.
- Integrated provenance logging for every interaction.
Advantages:
- Isolation from External Influence – No internet or vendor data contamination.
- Continuous Learning on Your Data – Model can be incrementally updated as schema evolves and queries are executed.
- Intrinsic Policy Awareness – Multi-tenancy, fine-grained permissions, and business logic are embedded in weights, not just prompts.
- Audit-Ready by Default – Every query generation event is logged, and the model’s training corpus is fully under your control.
- No Data Egress Risk – Queries and schema never leave your security perimeter.
In this model:
- User Input is parsed by your local fine-tuned LLM.
- Schema Context is retrieved via local RAG or fully internal schema memory.
- SQL Queries are generated within your policy constraints.
- Provenance Records are automatically stored.
- The model is continuously retrained or fine-tuned with approved new queries for ongoing alignment.
Custom Local LLMs Reference Architecture
A reference architecture and implementation approach for building fully local, schema-aligned, policy-aware Text-to-SQL models that operate without access to any external, ungrounded facts is an important part of any trustworthy AI initiative. The goal is to achieve maximum trust in AI-generated database interactions by combining fine-tuning on domain-specific data, strict security controls, continuous training, and provenance tracking.
Key Components:
- Schema Store: Machine-readable representation of DB schema, updated automatically.
- Training Corpus: Curated set of historical queries + policy annotations.
- Fine-Tuned Local LLM: Hosted on local inference infrastructure (GPU server or on-prem AI appliance).
- RAG Layer (optional): Retrieves relevant schema fragments for large or evolving databases.
- Provenance Engine: Logs prompt, schema context, generated SQL, execution plan, and result.
- Continuous Trainer: Periodically fine-tunes the model with new approved queries.
High-Level Data Flow:
User → Query Parser → (Optional RAG) → Local LLM → SQL Validator → Execution Engine
↓
Provenance StoreModel Preparation
Data Collection
-
Schema Export:
SELECT table_name, column_name, data_type FROM information_schema.columns WHERE table_schema = 'public'; -
Historical Queries:
- Extract from DB query logs.
- Filter by successful execution and policy compliance.
Data Curation
-
Annotate queries with:
- Tenant scope (e.g.,
tenant_id = :currentTenant). - Role permissions (e.g.,
role:admin,role:analyst). - Business rule compliance.
- Tenant scope (e.g.,
-
Remove:
- Unbounded destructive queries.
- Non-representative or experimental SQL.
Fine-Tuning Dataset Format
{"prompt": "Generate SQL for: Top 10 customers by revenue in 2024\nSchema: <...>", "completion": " SELECT name, SUM(revenue) ..."}
{"prompt": "Generate SQL for: List active projects for tenant_id=42\nSchema: <...>", "completion": " SELECT project_name ... WHERE tenant_id = 42;"}Training and Hosting
Model Selection
- Open-source base models with permissive licenses (e.g., CodeLLaMA, MPT, Qwen2.5-Coder).
- Parameter size tuned to local hardware and latency requirements.
Fine-Tuning Pipeline (Pseudocode)
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
# Load base model
model = AutoModelForCausalLM.from_pretrained("Qwen2.5-Coder")
tokenizer = AutoTokenizer.from_pretrained("Qwen2.5-Coder")
# Load and tokenize dataset
dataset = load_jsonl("fine_tune_dataset.jsonl")
tokenized = dataset.map(lambda ex: tokenizer(ex["prompt"] + ex["completion"]), batched=True)
# Training arguments
args = TrainingArguments(
output_dir="./local_sql_model",
per_device_train_batch_size=2,
learning_rate=5e-5,
num_train_epochs=3,
save_steps=1000,
fp16=True
)
# Train
trainer = Trainer(model=model, args=args, train_dataset=tokenized)
trainer.train()
# Save locally
model.save_pretrained("./local_sql_model")
tokenizer.save_pretrained("./local_sql_model")Inference Pipeline
Core Inference (Pseudocode in TypeScript/Deno)
import { generateSQL } from "./local-inference.ts";
import { validateSQL } from "./sql-validator.ts";
import { writeProvenance } from "./provenance.ts";
const userQuery = "Show top 5 products by revenue for current tenant";
const sql = await generateSQL(userQuery, "./schemas/postgres-schema.json");
if (!validateSQL(sql)) {
throw new Error("Policy violation in generated SQL");
}
const result = await executeSQL(sql);
await writeProvenance(userQuery, sql, result);
console.log("Query result:", result);Local Inference
// local-inference.ts
export async function generateSQL(userQuery: string, schemaPath: string) {
const schema = await Deno.readTextFile(schemaPath);
const prompt = `Generate a SQL query for the following request, using only this schema:\n${schema}\n\nRequest: ${userQuery}`;
// Local model inference API call
const resp = await fetch("http://localhost:8000/generate", {
method: "POST",
body: JSON.stringify({ prompt }),
}).then(res => res.json());
return resp.output;
}Continuous Training
Process
- Monitor provenance logs.
- Review and approve high-value queries.
- Append approved queries to training dataset.
- Retrain or LoRA-adapt model periodically.
Automation Pseudocode
import json, shutil
def append_to_dataset(provenance_dir, dataset_file):
for file in os.listdir(provenance_dir):
record = json.load(open(file))
if record["approved"]:
with open(dataset_file, "a") as ds:
json.dump({
"prompt": record["userQuery"] + "\nSchema: " + json.dumps(record["schemaContext"]),
"completion": " " + record["generatedSQL"]
}, ds)
ds.write("\n")
append_to_dataset("./provenance", "fine_tune_dataset.jsonl")Security Considerations
- Run inference in an air-gapped network for sensitive data.
- Apply role-based query filters pre- and post-generation.
- Enforce schema whitelists to prevent cross-tenant leakage.
- Log all inputs/outputs for audit readiness.
Here’s the new stand-alone paper as requested - "Custom Text-to-SQL: Combining AnythingLLM with Open Source Tools like Vanna or PremSQL" - designed to extend The Ultimate Trust Model: Custom Local LLMs into a concrete experimental reference architecture.
Experimentation-ready Architecture: Combining AnythingLLM with Open Source Tools like Vanna or PremSQL
Here is a practical, experimental reference architecture for building custom, schema-aware, policy-aligned Text-to-SQL systems by combining the orchestration and multi-model management capabilities of AnythingLLM with open source Text-to-SQL engines such as Vanna and PremSQL.
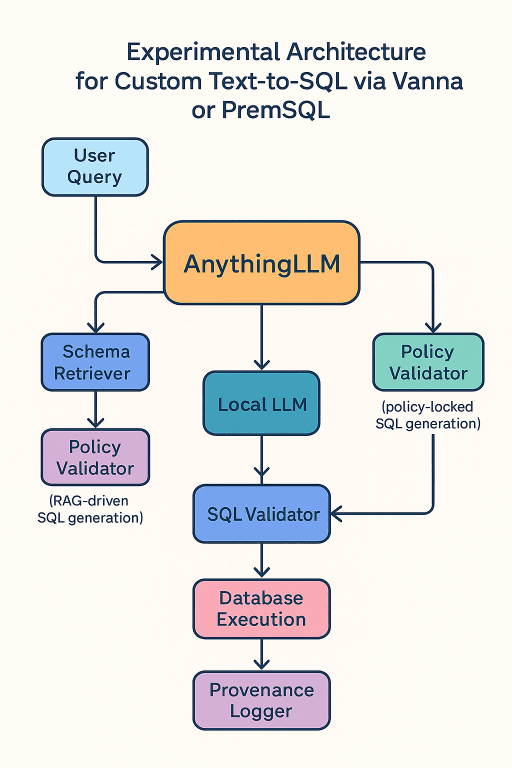
| Component | Role in the Architecture |
|---|---|
| AnythingLLM | Multi-model orchestrator, RAG engine, knowledgebase builder, API/UI gateway. Manages prompt chaining, schema retrieval, and user interaction. |
| Vanna | Python-based, RAG-driven Text-to-SQL generation tool with schema grounding. Great for retrieval-driven SQL creation and extensibility. |
| PremSQL | Fully local, privacy-first Text-to-SQL library, ideal for air-gapped deployments or strict compliance environments. |
| Local LLM | Fine-tuned model trained on schema, historical queries, and policies - no external, ungrounded facts. |
User Query
↓
AnythingLLM Orchestrator
├── Schema Retriever (local DB or vector store)
├── Policy Validator
├── Route to Engine
│ ├── Vanna (RAG-driven SQL generation)
│ └── PremSQL (policy-locked SQL generation)
└── Local LLM Inference Endpoint
↓
SQL Validator → Database Execution → Provenance LoggerAnythingLLM as the Orchestration Layer
- Hosts multiple local LLMs (e.g., CodeLLaMA, Qwen2.5-Coder, MPT) for fallback or A/B testing.
- Manages context injection from schema vector embeddings.
- Provides prompt templates enforcing schema-only rules.
- Handles multi-tenant routing - injecting tenant IDs, role constraints into prompts.
Vanna Integration
- Runs as a Python service connected to AnythingLLM.
- Uses RAG with embeddings of the schema and optionally query history.
- Accepts the user request and returns a candidate SQL statement.
- Ideal for exploratory queries and schema-aware joins.
PremSQL Integration
- Runs entirely locally without internet.
- Uses explicit schema mappings and controlled query templates.
- Ideal for locked-down, policy-critical workloads (e.g., regulated production queries).
Local LLM Fine-Tuning
- Fine-tuned using the dataset preparation flow from The Ultimate Trust Model.
- Hosted in AnythingLLM’s local model registry.
- Continuously trained from approved provenance logs.
Experimental Deployment Pattern
- AnythingLLM running in Docker on a secured local host.
- Vanna Python service exposed via REST API on the same network.
- PremSQL running as a local library in AnythingLLM’s plugin container.
- PostgreSQL or MySQL test instance with anonymized production schema.
- Vector store (Weaviate, pgvector, or Milvus) for schema embeddings.
-
Schema Ingestion. Export DB schema → embed with AnythingLLM → store in vector DB.
-
Query Handling
-
User sends a natural language query to AnythingLLM.
-
AnythingLLM retrieves relevant schema context.
-
Policy validator injects tenant/role constraints.
-
AnythingLLM routes request:
- Vanna path: retrieval-driven SQL generation.
- PremSQL path: template-driven, locked-down SQL generation.
-
-
Validation: SQL passes through syntax check, policy check, and optional execution in a staging environment.
-
Execution & Provenance: Results returned to user + full record (query, schema subset, model used, execution plan, result) stored as Markdown with frontmatter.
-
Continuous Learning: Approved provenance logs appended to training dataset → periodic fine-tuning of local LLM.
Pseudocode for Orchestrator Routing
def handle_user_query(query, engine="auto"):
schema_context = retrieve_schema_context(query)
policy_enforced_prompt = apply_policy_context(query, schema_context)
if engine == "vanna":
sql = vanna_generate_sql(policy_enforced_prompt)
elif engine == "premsql":
sql = premsql_generate_sql(policy_enforced_prompt)
else:
# Auto-select engine
if is_policy_critical(query):
sql = premsql_generate_sql(policy_enforced_prompt)
else:
sql = vanna_generate_sql(policy_enforced_prompt)
if not validate_sql(sql):
raise Exception("Invalid or unsafe SQL generated")
result = execute_sql(sql)
log_provenance(query, schema_context, sql, result, engine)
return resultBy combining AnythingLLM’s orchestration with Vanna and PremSQL’s specialized Text-to-SQL capabilities - and layering in local, fine-tuned models - this architecture provides a real, testable implementation path for The Ultimate Trust Model: Custom Local LLMs. It bridges the gap between high-level pseudocode and operational reality, creating a system that can be proven, audited, and evolved toward the highest possible trust in AI-driven database interactions.
Trust Alignment: A Unified Framework
Trustworthy AI in Text-to-SQL emerges when four pillars reinforce each other:
- Markdown Provenance – Canonical trust layer for every query, schema, and result.
- Schema-Aware RAG – Smaller, more relevant context to improve accuracy and safety.
- Custom Fine-Tuning – Schema and policy alignment baked directly into the model.
- Local Model Isolation – Prevents external ungrounded facts and enforces continuous, in-domain learning.
This alignment turns the model into a trusted intermediary:
- Capturing user intent.
- Translating it into safe, compliant SQL.
- Executing only within the bounds of your schema and policies.
- Returning explainable answers with full lineage.
Strategic Impact:
- Compliance-first by design.
- Reduced operational risk in multi-tenant, regulated environments.
- Scalable governance without sacrificing user experience.
In high-stakes environments, trust is engineered - not assumed. By combining provenance tracking, schema-focused retrieval, fine-tuned alignment, and fully local models, you transform Text-to-SQL from a convenience feature into a cornerstone of enterprise-grade trustworthy AI.
A custom, fully local Text-to-SQL LLM fine-tuned on your schema and historical queries, continuously trained on approved results, and isolated from external ungrounded facts delivers the highest achievable trust in AI-driven database access. This model transforms SQL generation from a generic capability into a governed, policy-aligned, explainable system suitable for mission-critical, regulated environments.
How is this guide?
Last updated on